Hexo博客百度收录(SEO)
曾迫不及待地想在百度上找到我的博文,可是找不到
后发现还要有百度收录操作才可显示
那就开始吧!
1. 百度搜索自己的域名,会发现找不到,显示
点击提交网址,并登录
提交好网站后没有下文……
2. 验证网站的所有权
登录百度站长平台 ,
登录成功之后在站点管理中点击添加网站然后输入你的站点地址,建议输入的网站为www开头的,
注意:不要输入github.io的,因为github是不允许百度的spider爬取github上的内容的,所以如果想让你的站点被百度收录,只能使用自己购买的域名
在选择完网站的类型后需要验证网站的所有权,验证网站所有权的方式有三种:文件验证,html标签验证和cname解析验证,使用哪一种方式都可以。
坑:我用的是文件验证
将验证文件放置于您所配置域名>(www.marmalade.vip)的根目录下
根目录是网站的source文件夹
但是
验证失败?
果断放弃!
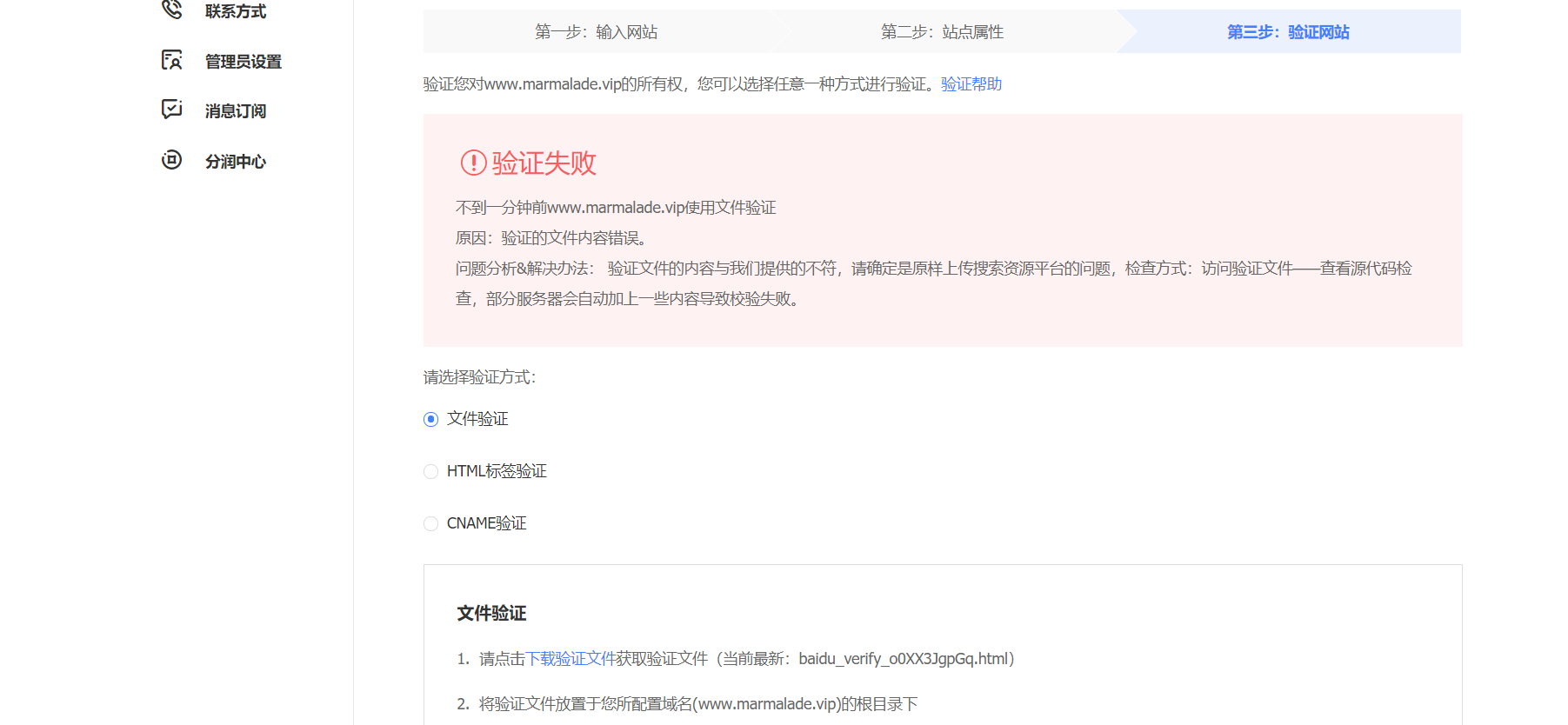
采用第三种cname方法
域名解析增加一条
成功!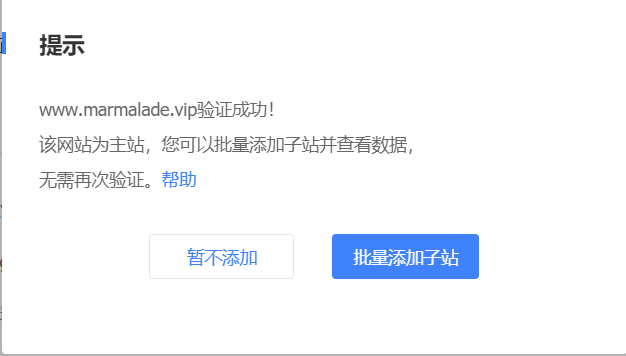
3. 生成网站地图
先安装sitemap插件
cmd添加两个插件
npm install hexo-generator-sitemap --save
npm install hexo-generator-baidu-sitemap --save12修改博客路径下的配置文件(非主题)中的url站点地址为自己网址
执行完之后就会在博客路径下生成sitemap.xml文件和baidusitemap.xml文件,
可以通过http://你的域名/baidusitemap.xml,
查看该文件是否生成,其中sitemap.xml文件是搜索引擎通用的文件,
baidusitemap.xml是百度专用的sitemap文件
4. 向百度提交链接
百度站长平台的数据引入,链接提交
选择主动推送
主动推送
安装插件
npm install hexo-baidu-url-submit –save
然后在根目录的配置文件中新增字段
baidu_url_submit:
count: 100 ## 比如100,代表提交最新的一百个链接
host: guoyanjun.top ## 在百度站长平台中注册的域名
token: your_token ## 刚刚复制的秘钥,不要公布到任何地方。
path: baidu_urls.txt ## 文本文档的地址,新链接会保存在此文本文档里在deploy里添加新的配置项
deploy:
- type: git # 原来就有的
repo: 巴拉巴拉
branch: master
message: blog update
- type: baidu_url_submitter # 注意,这个为新增的结果报错:???
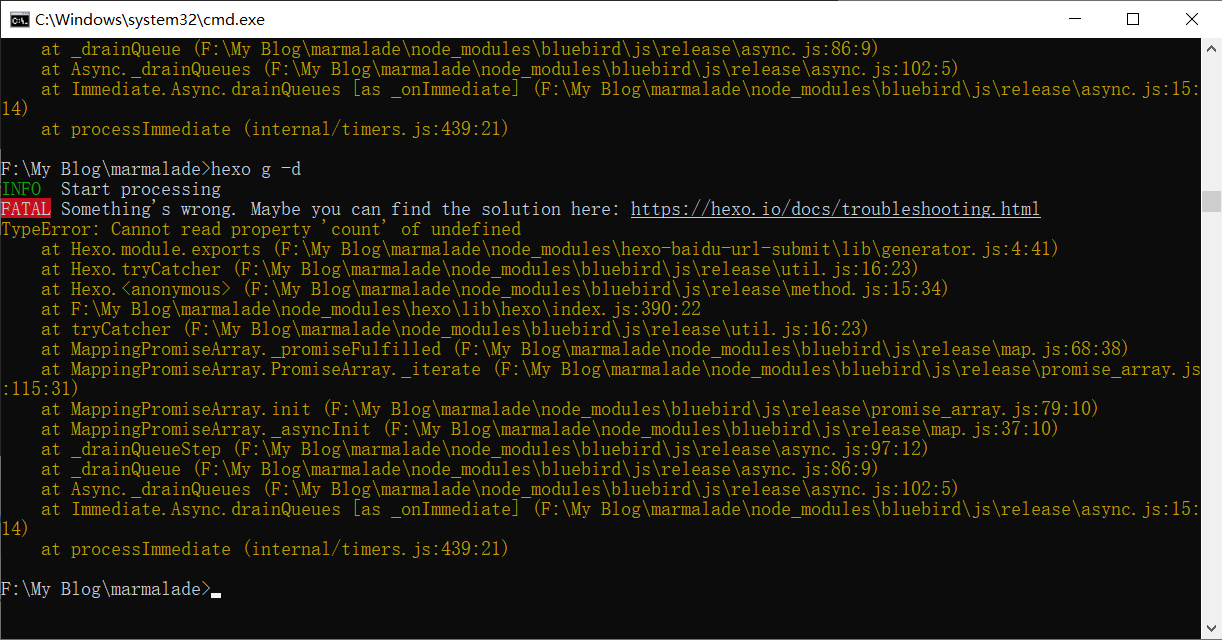
百度这个错误
hexo错误 TypeError: Cannot read property ‘count’ of undefined
解决方案:
npm remove hexo-baidu-url-submit
hexo clean
hexo g删除百度自动提交就好了。
可是删除了百度自动提交不就不行了???
暂时删除
以后每次hexo个 g -d
会提示
过了很久以后
忍不住又使用了一遍指令
npm install hexo-baidu-url-submit –save
结果这次hexo g -d不报错了!??
所以成功!
参考文章:
如何让hexo博文被百度收录
链接提交:自动推送
进入主题配置文件,开启baidu_push(fause变为true)
站点根目录\themes\next\layout_scripts目录,修改baidu_push.swig文件为以下内容,若无该文件直接创建一个
{% if theme.baidu_push %}
{% endif %}重新编译生成部署即可,这样每次访问一个页面都会主动把这个页面的地址提交给百度
访问博客任一页面,然后按F12,切换到Elements,如果看到如下代码说明以上js代码插入成功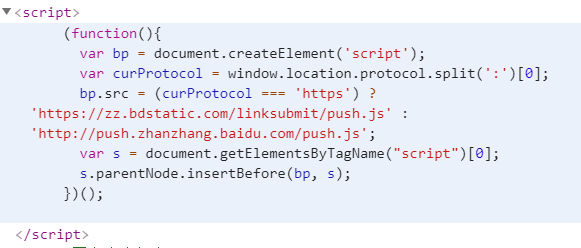
sitemap提交
在百度站长平台找到链接提交,自动提交中找到sitemap
将以下两行(域名写自己的)提交,然后等待回复就可以啦
https://marmalade.vip/baidusitemap.xml
https://marmalade.vip/sitemap.xml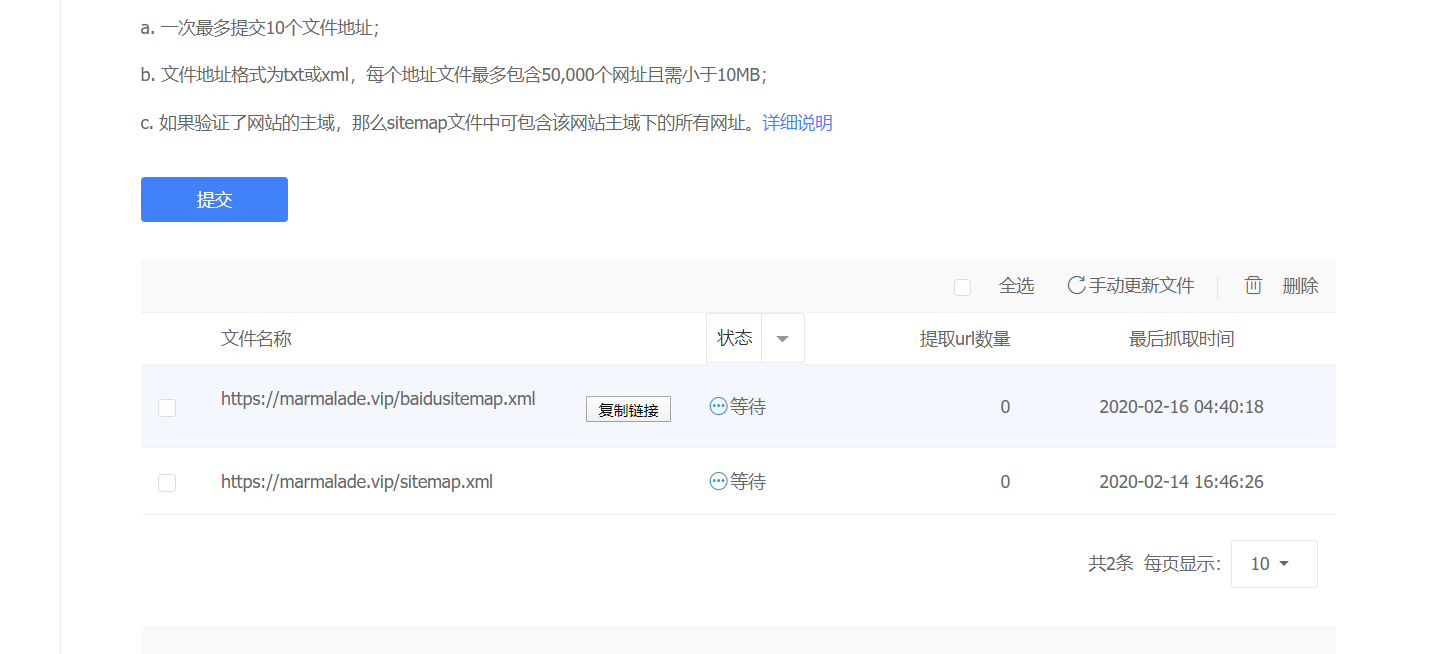
谷歌收录
需要范强才可,首先要有一个谷歌账号
打开该网址https://search.google.com/
登录后输入自己的域名会有DNS域名所有权验证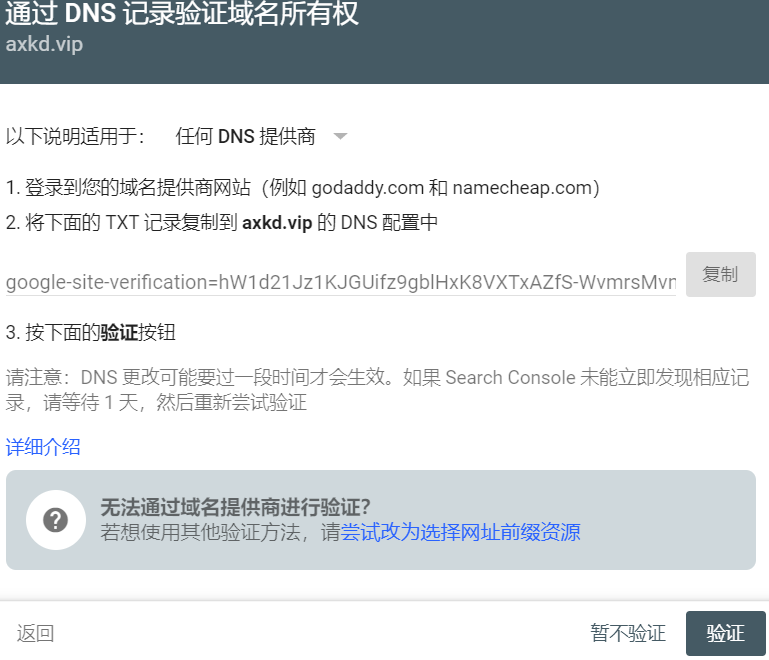
要用到域名解析,打开自己域名的域名解析界面,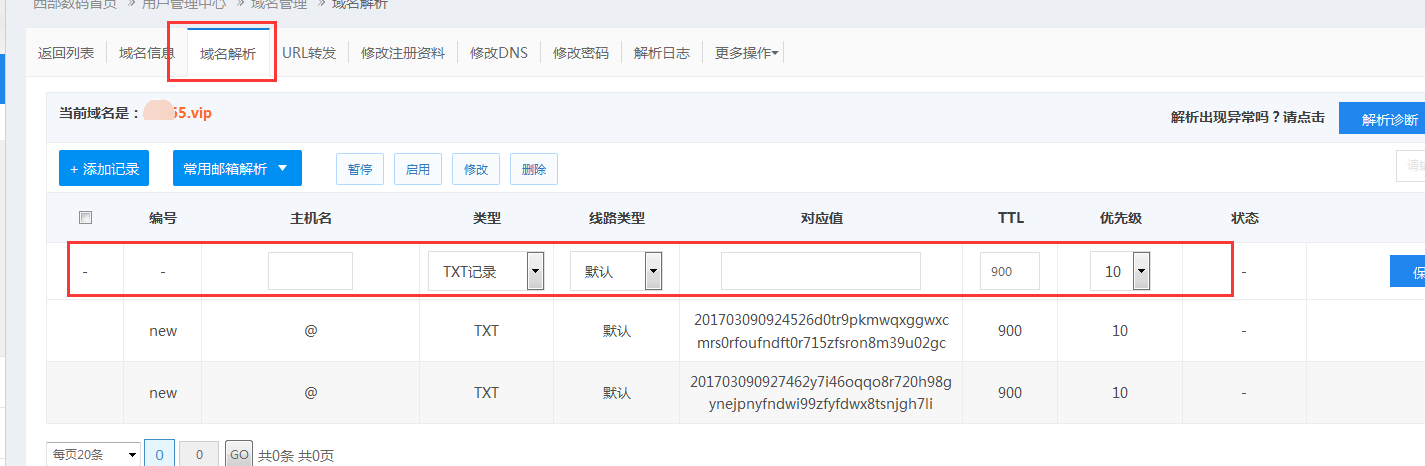
添加TXT记录,完成DNS验证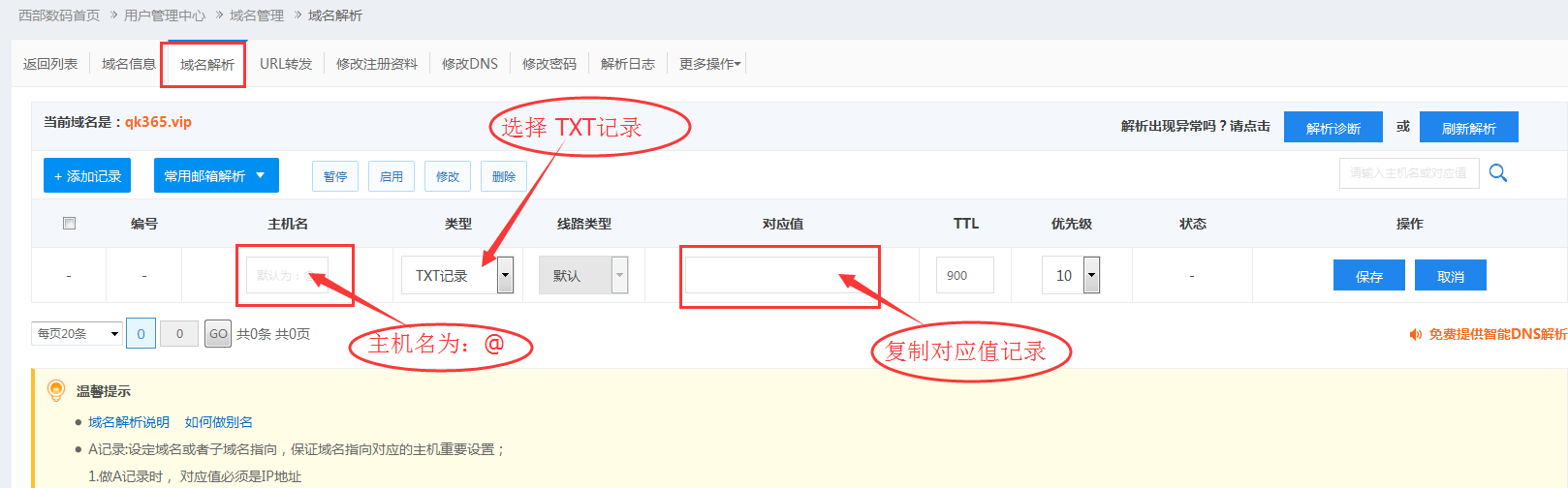
对应值:2017030909245xxxxxxxxxxxxxxxxxx(直接复制 “记录值”输入),
(如果是二级域名,比如west.qk365.vip,主机名就是 >“west”,对应值复制输入系统提示的 “记录值”)
然后等待一天后可进入管理页面
直接在站点控制台添加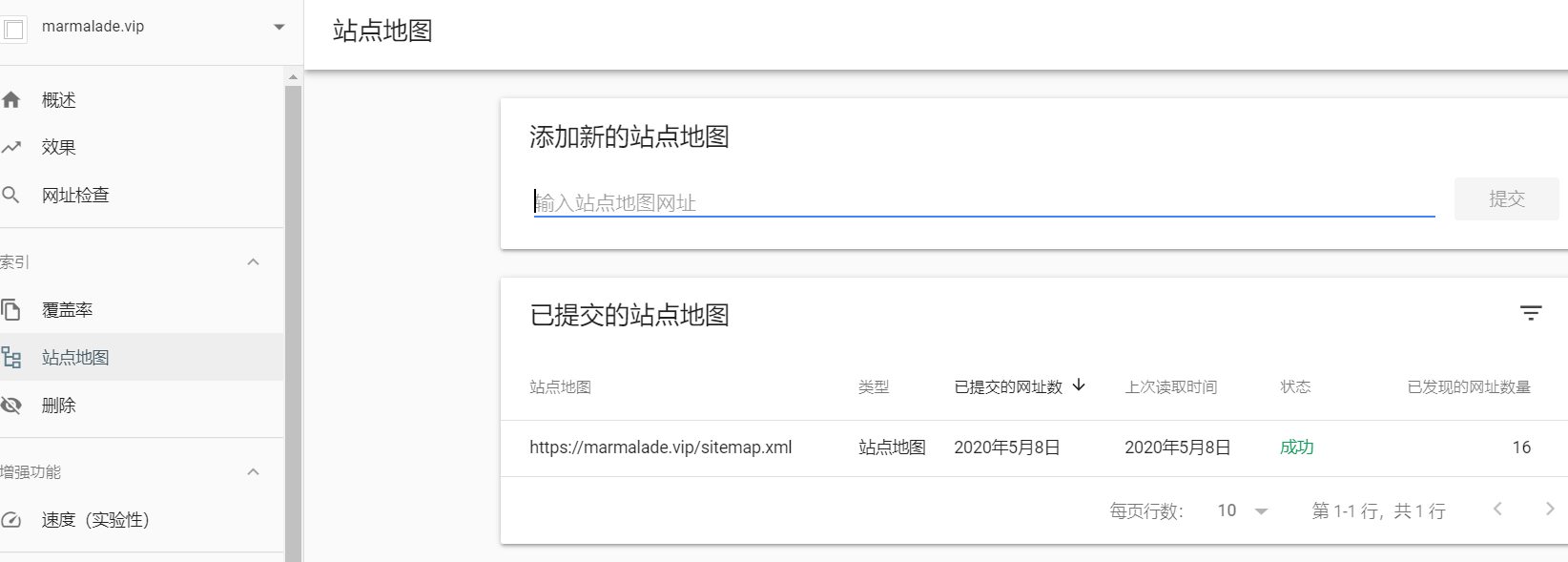
即提交成功
添加蜘蛛协议
蜘蛛协议就是告诉爬虫,你的哪些文件爬虫可以爬取,哪些不能的文件。新建一个robots.txt文件,添加以下内容,然后放到/yoursite/source/文件夹下面:
User-agent: *Allow: /
Allow: /archives/
Allow: /tags/
Allow: /categories/
Allow: /about/
Disallow: /js/Disallow: /css/
Disallow: /lib/
Sitemap: 刚刚sitemap的地址在百度站长平台,左侧,Robots里面可以检测你写的是否正确: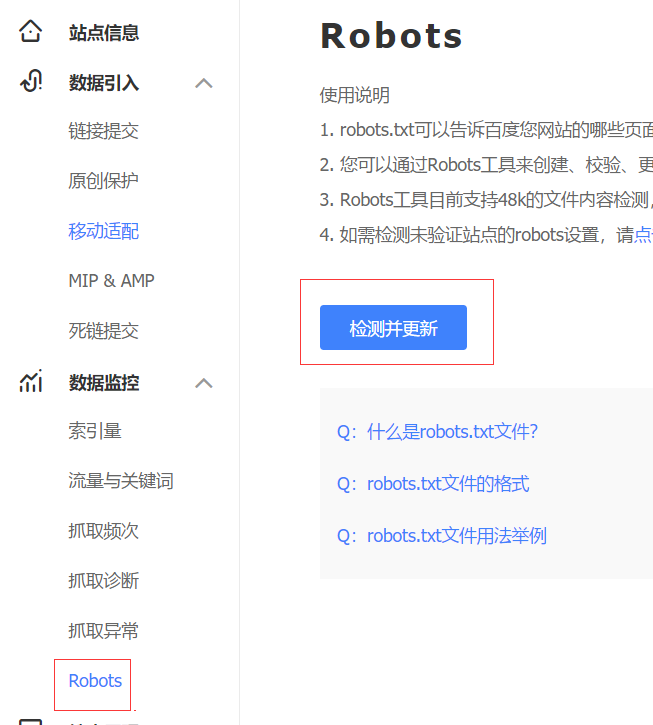
(禁止爬虫跟踪外链)
当你提交了链接,写好了蜘蛛爬取协议之后,搜索引擎的蜘蛛就会来爬取你的文章内容。但是,如果你的文章中有外链,蜘蛛就会通过这个链接到别人的站点去。如果这个站点是友情链接还好,如果是非友链,就回严重影响网站的爬取。
为了避免蜘蛛进入非友情链接,需要为非友链添加上nofollow属性。推荐使用hexo-autonofollow插件。
在站点根目录下执行:
npm install hexo-autonofollow --save修改站点配置文件,添加如下内容:
nofollow:
enable: true
exclude: # 例外链接
- 你自己的站点地址
- 友链地址这样,例外的链接就不会被加上nofollow属性。
注:插件自动添加的属性为external nofollow noopener >noreferrer。一般来说标准的nofollow属性只需要external >nofollow即可,noopener noreferrer估计是新闻上说的钓鱼漏>洞的补救方法,不过这条属性会影响站长工具的友链检测。
如果想要去掉noopener noreferrer,修改/yoursite/node_modules/hexo-autonofollowlib/filter.js:
rel: 'external nofollow noopener noreferrer'去掉其中的noopener noreferrer,再生成即可。



